Versioning graph data is a complex challenge, particularly when it comes to tracking changes over time in a way that is both efficient and scalable. It is key to collaborative, scalable enterprise graph solutions that ensures consistency, provenance, and preserves semantic integrity as foundational artifacts evolve over time. One of the key considerations in graph data versioning is how to manage the history of changes—should deltas be stored in a forward or reverse manner, and what is the most efficient way to reconstruct the state of the data at any given point? Traditional forward deltas, where each change is stored in chronological order, have been the go-to solution for many systems, offering quick retrieval of changes and simplified logic for applying updates. However, these systems often struggle with inefficiencies when trying to compile the current state from a long history of changes, leading to high computational costs. Mobi, for instance, has faced these challenges in its long-term use of forward deltas to version RDF data. To address these issues, Mobi has reimagined its approach by adopting reverse deltas, flipping the history structure to store changes that reflect what needs to be undone to reach a previous state. This inversion of the versioning model not only improves performance by always keeping the latest state easily accessible but also enables faster querying, better insights into the data, and more efficient management of long version histories.
How Should Graph Data be Versioned?
Versioning graph data presents a significant challenge, with numerous factors to consider when determining the best approach. How can you effectively track changes to a model over time? Should the data be serialized and stored in plaintext and versioned with a tool like Git? Or should deltas be stored directly in a triplestore? How do you efficiently compile these deltas to reconstruct the graph’s state at any given moment? And how does introducing a branching structure, similar to Git, impact these decisions? Navigating these questions requires balancing performance, flexibility, and scalability to find the most effective solution.
How Has Mobi Handled Versioning?
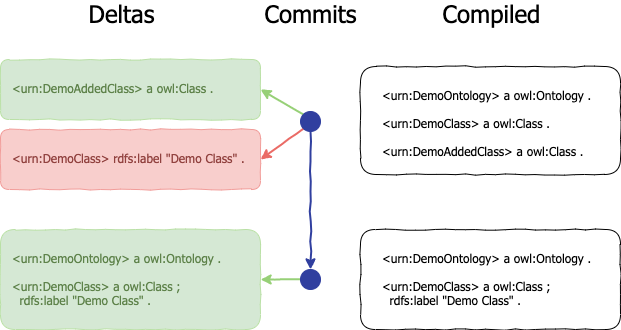
For nearly a decade, Mobi has used forward deltas to version RDF data, storing them natively within a triplestore. Each delta represents the changes made to the graph relative to the previous state. This approach has offered several advantages over the years, including fast retrieval of changes at a specific commit, minimal computation when writing changes, and straightforward logic for calculating the state at a particular point in time—simply applying the deltas in chronological order from the start of the history. While this system has been foundational to Mobi’s core functionality, it has also revealed significant limitations over time. To compile and view the most recent changes, every delta in a Versioned RDF Record must be processed, which can be computationally expensive and time-consuming, especially for records with extensive version histories. Furthermore, because the latest state is not stored at any given time, it’s not possible to easily derive insights—such as the number of entities or statements—without going through the entire compilation process. Despite optimizations in compilation and caching, the process of retrieving the latest state remains resource-intensive. Ultimately, since users primarily care about the most up-to-date state of a Versioned RDF Record, avoiding the computational cost of continuous compilation would significantly improve the platform’s speed and overall performance for the most common use case: working with the latest data.
What’s a Better Paradigm for Graph Versioning?
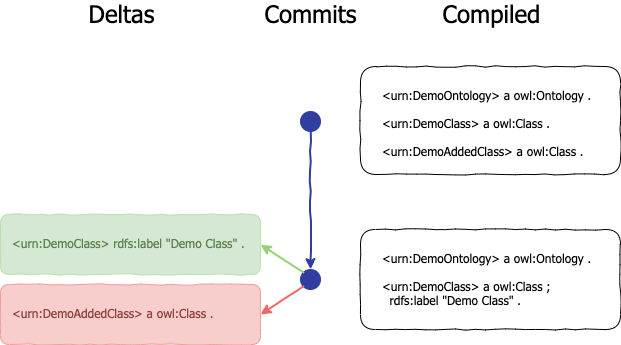
In version 4.0, the Mobi team made a pivotal decision to overhaul its core functionality by “inverting” the history structure, shifting from using forward deltas to storing reverse deltas natively. While forward deltas capture the changes made at each point in time relative to the previous state, reverse deltas represent the changes needed to revert to an earlier state as we move backwards through time. This new paradigm offers a significant advantage: by always storing the latest state of a Versioned RDF Record, the system ensures that the current state is easily accessible at any point. This makes it possible to work backward from the most recent state to reconstruct any previous state as needed. Inverting the commit history to use reverse deltas also brings several other key benefits. With the latest state always available, it becomes straightforward to derive insights, such as statistics on the number of entities and statements in a Versioned RDF Record. Additionally, searching across multiple Versioned RDF Records is now possible—enabling quick queries to find which records contain a specific term. Another notable advantage is the improved performance during initial loads. Since the latest state is readily available, there’s no need to iterate through the entire delta history, making the process much faster, especially for records with extensive version histories.
Where Do We Go From Here?
With Mobi now leveraging the benefits of its new “inversioned” data structure—enabling powerful features like real-time statistics and entity search—what new possibilities lie ahead? In the near term, the Mobi team plans to further enhance performance by accelerating the caching process through federated queries across both the system repository (where the latest state of Versioned RDF Records is stored) and the Versioned RDF Record cache (which temporarily stores different loaded historical states). This will result in particularly significant performance improvements for Versioned RDF Records that import other records from the system, as imported records will no longer need to be reloaded into the cache, streamlining operations and reducing overhead.
Beyond caching, the Mobi team has exciting plans to build additional features that capitalize on the strengths of this “inversioned” structure. Stay tuned for upcoming releases, as these innovations promise to deliver even more powerful capabilities and greater efficiency.







